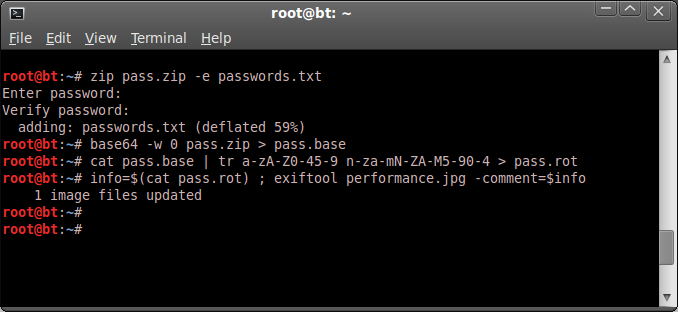
Substitution ciphers are a frequent part of many online challenges and CTF competitions, and are always fun to have a look at.
Most of these types of ciphers are fairly easy to crack with just a pencil and paper method, but there are other, quicker ways to get the job done as well.
The most frequently seen letter substitution ciphers are;
> Caesar shift ciphers
Shifting the letters of the alphabet up a fixed number of letters to encode / decode a given text.
> Substitution ciphers
Replacing the letters of the alphabet with randomly chosen letters to encode a given text.
> Position dependant shift ciphers
Replacing letters at a certain position with a shifted value and repeating that position shift cycle on each word or sentence.
CAESAR SHIFT CIPHERS
=====================
These are the easiest to identify and decode.
Decoding can be done by simply writing out the alphabet and identifying the shift by trial and error and testing the (expected) correct outcome.

The most well known Caesar shift is the so-called ROT13, which can be used to both encode and decode a message by shifting the letters up 13 positions.

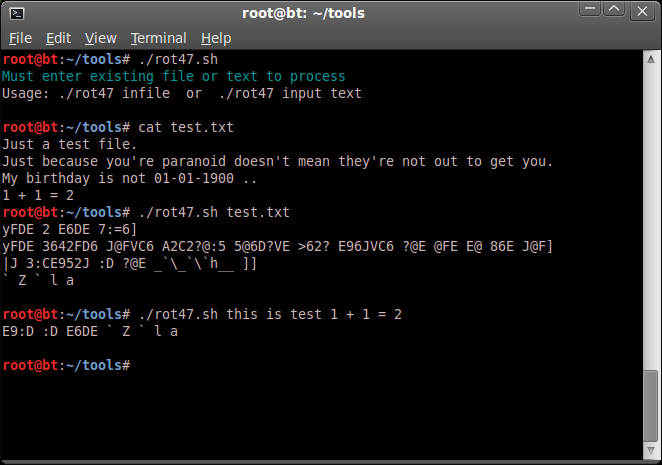
ROT13 messages are easy to encode / decode with a short one-liner using 'tr' ;
echo "This is a test, one plus one is two" | tr a-zA-Z n-za-mN-ZA-M
This can be expanded to included digits as well (sometimes referred to as ROT18), by replacing 0-4 with 5-9 and 5-9 with 0-4 ;
echo "this is a test, 1 + 1 = 2" | tr a-zA-Z0-45-9 n-za-mN-ZA-M5-90-4
The same principle of shifting letters can be used with any number of shifts.

The easiest way to check for a Caesar shift cipher is to check all the possible shifts of a word, or sequence of words, and verify at what shift the text becomes readable.
There are quite a few scripts / websites which can check and do this for you, but as a lot of them have some kind of limitation, and as I am one who enjoys re-inventing the wheel ;) I decided to have a crack at making a bash script doing the same as well.
Introducing cshift
Download: http://www.mediafire.com/view/a9vnps7p015agpy/cshift_v0-4.sh
Unlike many other solutions found on the interwebz, cshift allows upper and/or lower case, negative values, as well as values higher than 26 (so for instance a shift of -5 characters or of +49 characters)

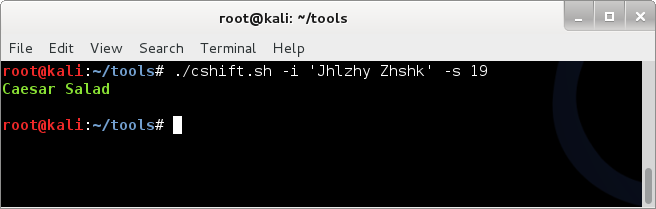
Running cshift on direct input (quotes!);
./cshift.sh -i 'Jhlzhy Zhshk' -s 19
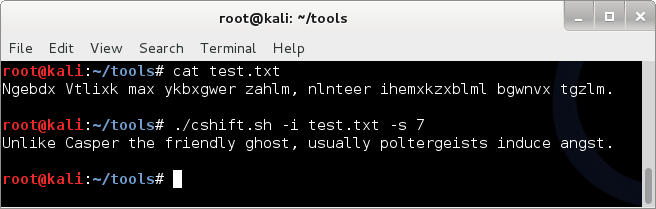
Running cshift on an example text file 'test.txt' ;
cat test
./cshift -i test.txt -s 7
'Bruteforce' checking of all possibilities.
Lets have a look at the following text (and assume it is part of an encoded text file)
(different shift value used, not the same as the above example) ;
hgdlwjywaklk afvmuw sfyklUsing cshift's -b switch for the 'bruteforce' function, we can check all the possible shifts and see which shift gives a readable outcome (this is best done on a short sequence of words, to be able to correctly ascertain shift values).
./cshift.sh -i 'hgdlwjywaklk afvmuw sfykl' -b
(dont like colours ? add the -c switch; ./cshift.sh -i 'hgdlwjywaklk afvmuw sfykl' -bc)

For possibly less well known words (or if the above colours have half blinded you preventing recognition of readable text..), this can be further simplified, by using cshift's -w switch which allows the the bruteforce output to be checked against a given dictionary or wordlist (use a small wordlist! its slow..).
In this case I have chosen to check against the UKACD list, which is a small wordlist for crossword puzzles etc.
For correct results this test should be done on a single long word (this also helps avoid false positives).
./cshift.sh -i 'hgdlwjywaklk' -b -w ukacd.txt

So with either just the 'bruteforce' -b switch or together with the -w switch we can see that a shift of 8 letters gives readable text and can use that value to decode the full text / text file.
SUBSTITUTION CIPHERS
======================
These are slightly harder depending on the amount of text given to work with.
The less text you have to work with, the harder it is.
Given a substantial amount of text, you can run a letter frequency analysis on the text and check the most frequent letters to create a starting point.
From there it is a matter of a decent vocabulary combined with some trial and error.
When looking at a text encoded with a substitution cipher, it is handy to take note of few things (based on text being in English);
- The letter 'E' is the most frequent letter in English, so it stands to reason that the most frequent letter in the encoded text could stand for an 'E'.
- The letter 'T' is the 2nd most frequent letter in English.
- Look for single character words; in an English text single letter words will be either 'A' or 'I'.
- The word 'the' is the most frequent 3-character word used in English, it is also the most frequently used word in general in English.
Some helpful information on letter and word frequencies in English can be found here;
http://scottbryce.com/cryptograms/stats.htm
Let's have a look at a test file 'manifesto.txt'
Using the -f switch in cshift we can do a rudimentary letter frequency analysis on the above text file;
./cshift.sh -i manifesto.txt -f

Now we have the letter analysis on the whole file, lets cut out the first few lines and work on those for a bit ;
head -n 25 manifesto.txt > new.txt
cat new.txt

From the previous letter frequency analysis it looks most likely that ;
K = E
A = T
We see that there are single letter words in use u & w
So, either ;
U = A & W = I or U = I & W = A
From the use of apostrophes noted in the text following U, it seems that U == I & W = A
I use a simple replacement/substitution script using 'sed' with lines written out line by line to make it easier to check and alter as needed.
To make it 'easier' to read I lower case all letters in the text and put substitutions in upper case, then keep on running it on the text file with expected substitutions until words start appearing.
#!/bin/bash(This actually also included in cshift with the -r switch,[./cshift -i input.file -r] but not practical as using it means continuous editing of the script in nano and possibly risking fubarring the whole script ;) use with care !)
#replace.sh
cat $1 | tr '[:upper:]' '[:lower:]' | sed \
-e 's/a/a/g' \
-e 's/b/b/g' \
-e 's/c/c/g' \
-e 's/d/d/g' \
-e 's/e/e/g' \
-e 's/f/f/g' \
-e 's/g/g/g' \
-e 's/h/h/g' \
-e 's/i/i/g' \
-e 's/j/j/g' \
-e 's/k/k/g' \
-e 's/l/l/g' \
-e 's/m/m/g' \
-e 's/n/n/g' \
-e 's/o/o/g' \
-e 's/p/p/g' \
-e 's/q/q/g' \
-e 's/r/r/g' \
-e 's/s/s/g' \
-e 's/t/t/g' \
-e 's/u/u/g' \
-e 's/v/v/g' \
-e 's/w/w/g' \
-e 's/x/x/g' \
-e 's/y/y/g' \
-e 's/z/z/g'
echo
exit 0
Let's enter the aforementioned probable substitutions in the replace.sh script and check the outcome.
./replace.sh new.txt

From that outcome it becomes clear that ;
X = H
And also following the use of apostrophes we can deduce that ;
N = S
After entering the above and re-running the script, from the part of text that is (semi-)readable we can further deduce that ;
D=N
M=M
And with a calculated guess (based on thinking of the word TEACH) try T = C

Now you are already well on your way in just a couple of steps.
Going through the text carefully, you will find that ;
R = K
S = R
L = D
Y = Y
O = L
Entering those values in the script and running it ;

Now its easy to identify the other letters and solve the text ;
q = F
v = B
f = W
p = O
c = G
i = U
j = V
e = P
g = J

Now to show you how to make it even easier ;)
lightningmanic shared a great frequency_analysis java script on the THS forums, including excellent explanations on substitution ciphers and the decoding of same.
This java script does a much better job than my attempts with the above bash scripts and should definitely be in your toolbox if you enjoy this kind of thing.
Download FreqA ;
http://www.mediafire.com/download/y1f6pjbyae3xkjb/FreqA.zip
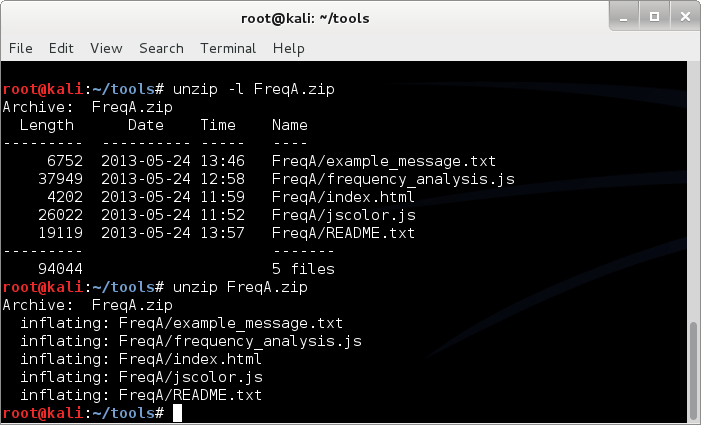
Check the FreqA.zip file contents and then unzip ;
unzip -l FreqA.zip
unzip FreqA.zip
Then open the index.html file in your web browser.
As written in java it should work on most modern browsers in most OS'.


The script is awesome, it shows the letter frequency analysis, most common two and three letter sequences, and a very quick and easy way to check substitutions.
For quick checks on letter substitution encoded text , this script is definitely what I will be using first.
Thanks for the share lightningmanic !
POSITION DEPENDANT SHIFT CIPHERS
===================================
These are more complicated to find and sometimes come with a hint, sometimes left for the user to figure out.
There are too many variations to go through into it in much depth, but the idea is to basically have the letters shifted a number of letters depending on their position in the word or sentence.
So for instance the word 'computer' with the shift '2, 4, 6.. ' could be encoded into ;
c=(c + 2) == E
o=(o + 4) == S
m=(m + 6) == S
p=(p + 8) == X
u=(u + 10) == E
t=(t + 12) == F
e=(e + 14) == S
r=(r + 16) == H
It comes down to a lot of trial and error, in the past I have used a 'template' like the below to stare at thinking of possibilities.

There are so many possible varations that it can be quite a daunting task and deciphering such an encoded message becomes a lot harder, however with sufficient text and quite a bit of trial and error, success can be achieved !
Should you feel inclined to give the scripts mentioned in this post a whirl, please let me know if any unexpected errors or weird output is encountered.
Edit 30-07-2013
---------------------
I'll admit I do like the fact that people take an interest and take the time to download scripts that I put up here :)
Sofar, over 100 people have taken the interest to do so, and I would be very interested to hear their thoughts on the cshift script !
(be gentle... ;) )
I truly do appreciate feedback, and although I am only a hobbyist in this field and the code will make many eyes bleed, your thoughts on the script and possible improvements are always appreciated !
Thanks for trying it out !