Work In Progress !
==================
A script to facilitate the commonly used options to make an existing
wordlist more to your liking..
Downloads below and based on using the script in Backtrack although it should work
in most Linux environments.
Google code + WIKI ; http://code.google.com/p/wordlist-manipulator/
Edit 21-10-2012
Release of WLM v0.7 ;
http://www.mediafire.com/file/p1tn76qw95hobi4/wlm
Video using WLM in BackBox ;
http://www.youtube.com/watch?v=FpflByHLp1I
--------------------------------------------
INTRO
After my posts from just over 2 years ago (wow... thought I would have learned more by now .. )I thought it would be a good idea to have another, more detailed post on wordlist manipulations based on 'simple' one-liners or simple scripts (sometimes 1 line just doesn't cut it) which can be run over the wordlist.
For some reason I always manage to forget the best way to do the simplest of things using sed and the like, so this is as much a reference for me, as it is hopefully some help to those looking for quick answers !
My intention is that queries on wordlist manipulation posted in the comments are looked at and tested
and then, I will try to post the best solution in doing same.
There will be quite a bit duplication from the previous post on wordlist manipulation, but no harm in that,
I find myself returing to 'old' info all the time..
MANIPULATING WORDLISTS
When you have a wordlist, it often needs fine-tuning or alteration of some kind in order to get the
most out of it, sometimes heavy-duty alteration, other times minor adjustments such as splitting the wordlist into manageable sizes or capitalizing the first letter for instance.
The below examples are based on wordlists that have already been created and need some sort of tweaking or fine tuning.
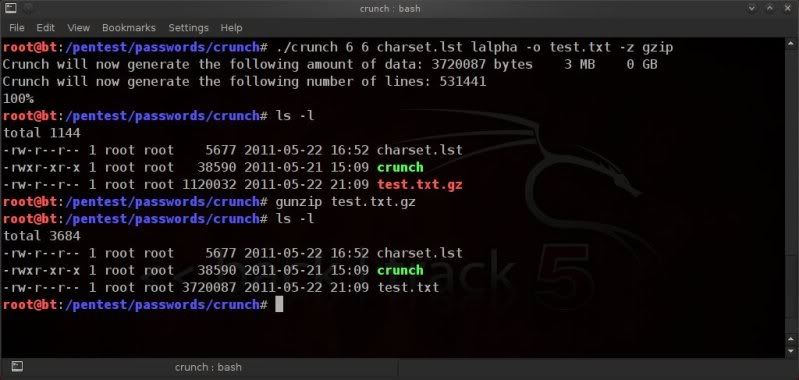
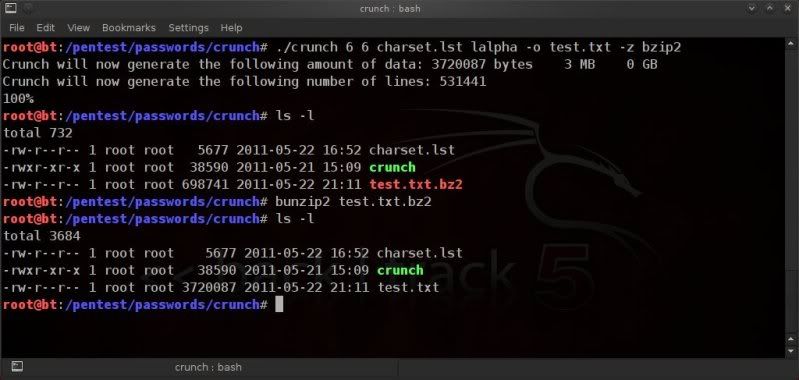
Of course you can create wordlists from scratch how you like with for instance crunch, however this post is meant solely for altering existing wordlists.
Note that the below examples all done on BackTrack5 and not tested on any other OS.
(although most commands should work on most linux based OS')
SPLITTING WORDLISTS
One of the main issues with wordlists is that they can get hellish big.. and you may need to split them for;
> for easy storage on portable drives,
> some programs only accept a certain maximum wordlist size,
> distributing segments of the wordlists to have tested by others,
etc.
etc.
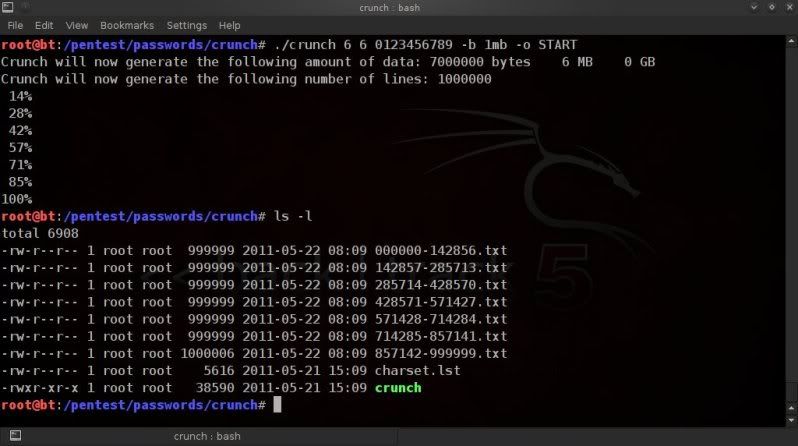
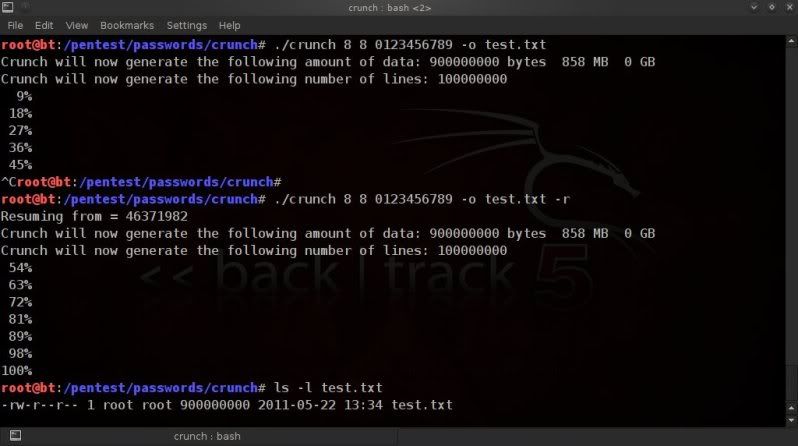
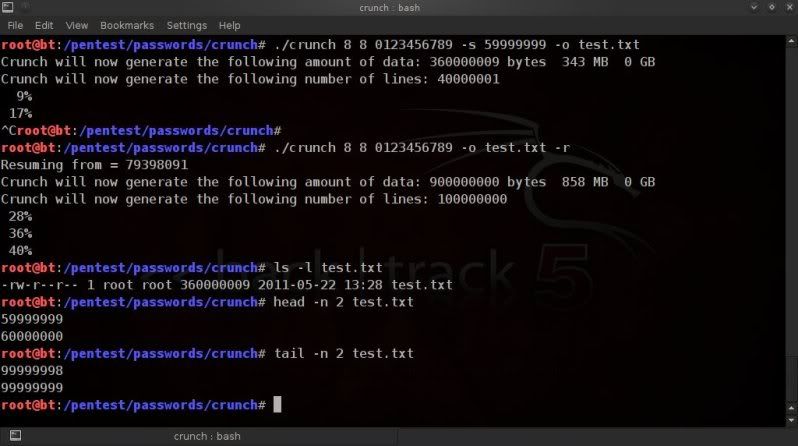
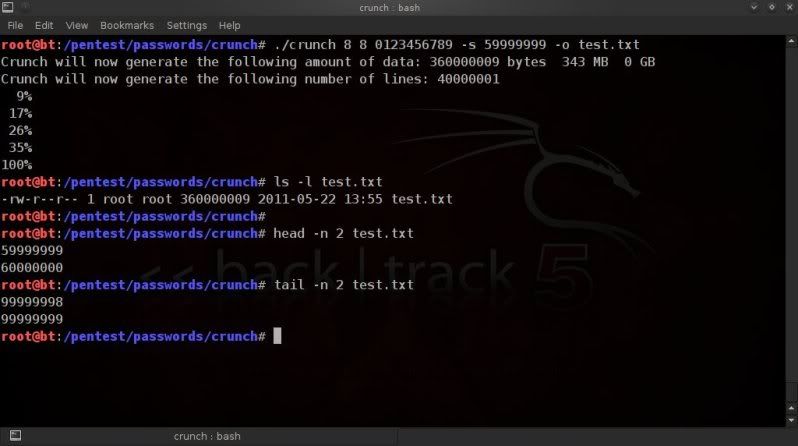
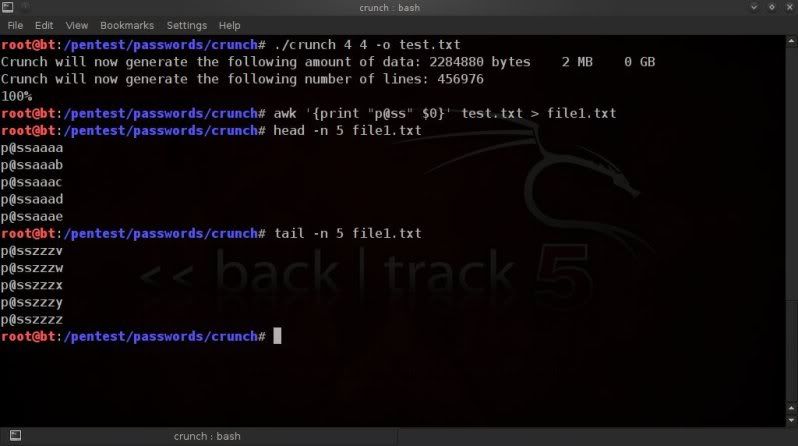
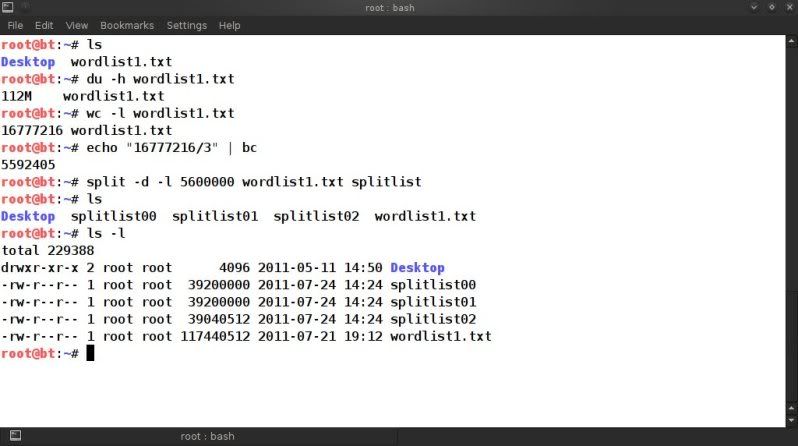
First thing to do is to check the size of the file and how many lines(passphrases) are in it so you can estimate
how you can best split it.
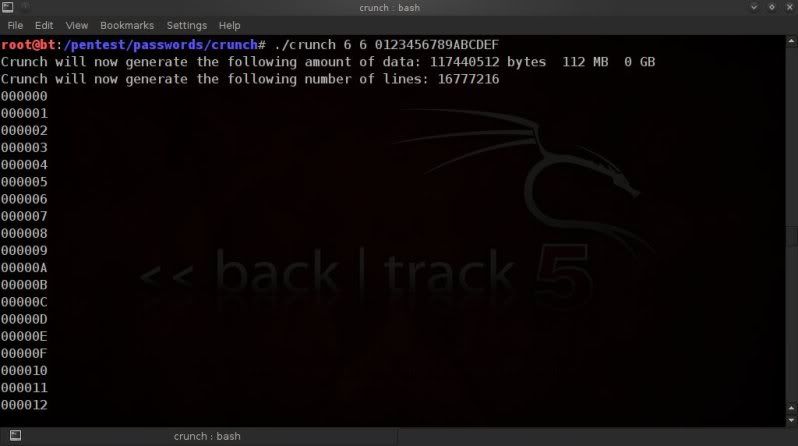
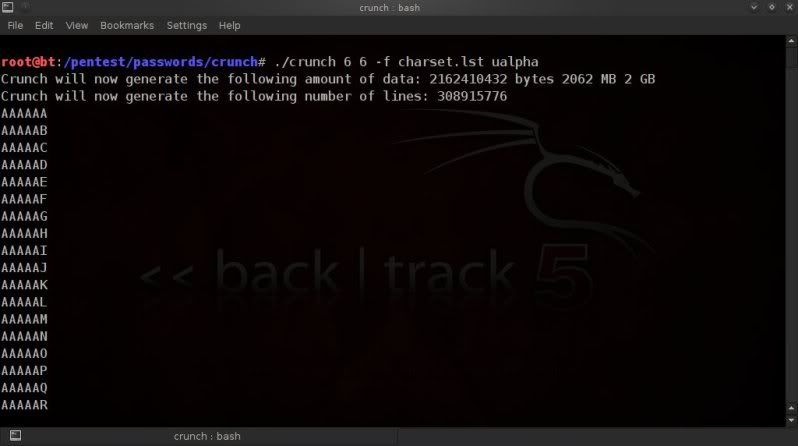
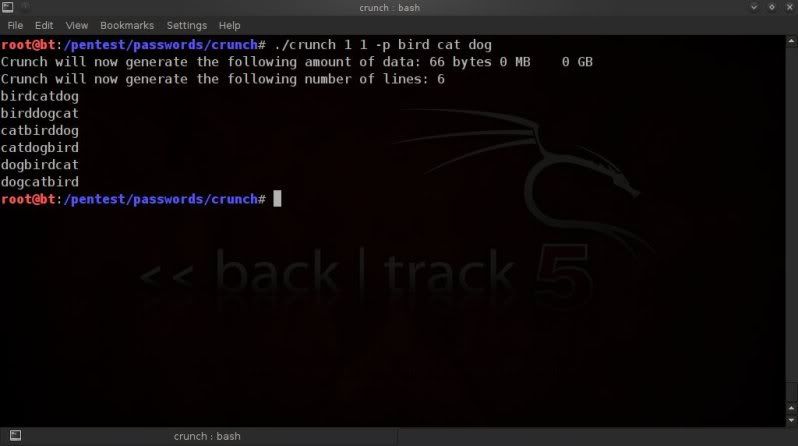
In this case using a 6 digit wordlist with lowecase alpha values only.
Check the size of the wordlist ;
For info on size in bytes ;
du -b wordlist1.txt
orSimple view of size in 'human readable' format (eg. 100K, 100M, 100G);
du -h wordlist1.txt
Get the linecount of the wordlist ;
wc -l wordlist1.txt
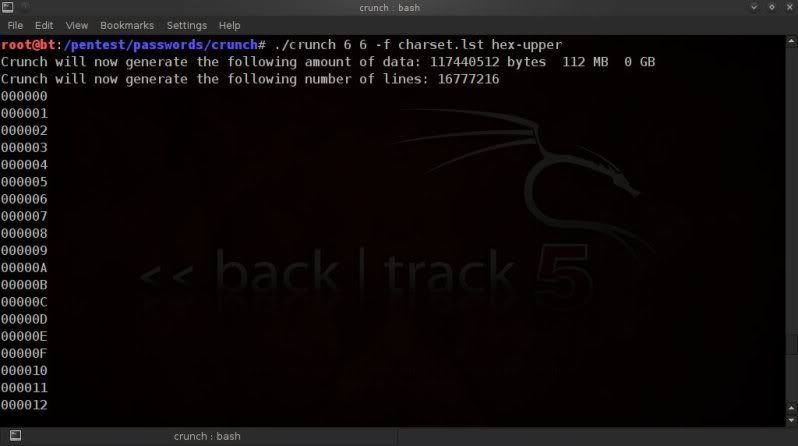
So in the above example the size is around 112MB and there are 16777216
lines (so 16777216 passphrases).
When using split to split wordlists, it is best to use split by line count, so that you don't accidentally split the actual words as can happen when you split by size.
Lets say we want to split that file into 3 wordlists, then the above file would need to be split into files containing +-5.500.000 words each.
If you are too lazy to work the little grey cells, let 'bc' do the work for you so you can make an educated guess on how many lines you want to have per split wordlist ;
echo "16777216 / 3" | bc
split -d -l 5600000 wordlist1.txt split-list
-d == giving a numeric suffix to the created split-list prefixes-l == giving the number of lines you want each file to have as a maximum
wordlist1.txt is the input wordlist
splitlist is the prefix for the newly created split files.
JOINING/COMBINING WORDLISTS
To actually combine seperate wordlists to one list, you can use the 'cat' command as follows ;
cat wordlist1.txt wordlist2.txt > combined-wordlist.txt
Depending on the size of your wordlists this can take a wee while..
You can also combine all .txt files in a directory to one larger file ;
cat *.txt > combinedlists.txt
CHANGING THE 'CASE' OF LETTERS IN A WORDLIST
Changing characters in a wordlist at a given position to either lower case or upper case is a frequent necessity.
Of course wordllists can easily be created with the required case in the required position (see my post on using the awesome crunch) however if you have an existing wordlist (which this post is all about) and need
to adjust the cases as required, this is (one of the ways) how to go about it.
First letter;
sed 's/^./\u&/' wordlist.txt
Last letter;
sed 's/.$/\u&/' wordlist.txt
CHANGING LETTERS TO LOWER / UPPER CASE
Changing the first letters of all entries to upper case ;
sed 's/^./\u&/' wordlist.txt
Changing the last letter of all entries to upper case ;
sed 's/.$/\u&/' wordlist.txt
Changing the first letter of all entries to lower case ;
sed 's/^./\l&/' wordlist.txt
Changing the last letter of all entries to lower case ;
sed 's/.$/\l&/' wordlist.txt
Changing all upper case to lower case letters;
tr '[:upper:] ' '[:lower:]' < wordlist.txt
Changing all lower case to upper case letters;
tr '[:lower:]' '[:upper:]' < wordlist.txt
Inverting the case in the words ;
tr 'a-z A-Z' 'A-Z a-z' < wordlist.txt
orsed 'y/abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ/ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz/' wordlist.txt
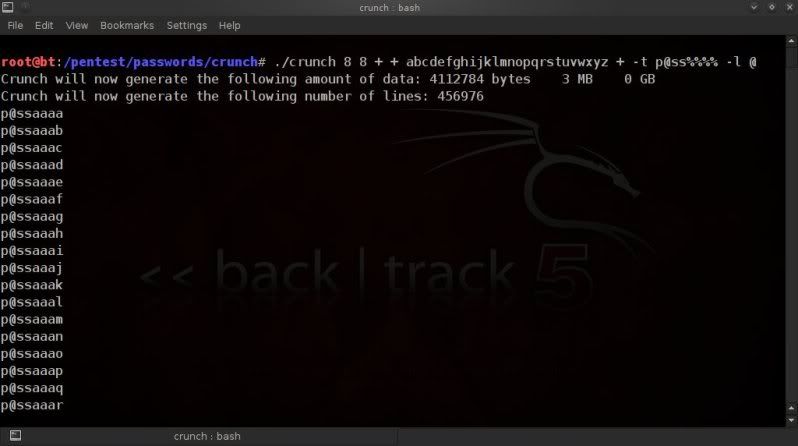
PREFIXING CHARACTER(S)/WORDS TO WORDLISTS
To prefix the word "test" to all lines in the wordlist ;
sed 's/^./test/' wordlist.txt
or
awk '{print "test" $0 }' wordlist.txt
PREFIXING NUMERIC VALUES TO WORDLISTS
To prefix 1 digit in sequence from 0 - 9 ;
for i in $(cat wordlist.txt) ; do seq -f %01.0f$i 0 9 ; done > numbers_wordlist.txt
To prefix 2 digits in sequence from 00 - 99 ;
for i in $(cat wordlist.txt) ; do seq -f %02.0f$i 0 99 ; done > numbers_wordlist.txt
To prefix upto 2 digits in sequence from 0 - 99 ;
for i in $(cat wordlist.txt) ; do seq -f %01.0f$i 0 99 ; done > numbers_wordlist.txt
To prefix 3 digits in sequence from 000 - 999
for i in $(cat wordlist.txt) ; do seq -f %03.0f$i 0 999 ; done > numbers_wordlist.txt
To prefix upto 3 digits in sequence from 0 - 999 ;
for i in $(cat wordlist.txt) ; do seq -f %01.0f$i 0 999 ; done > numbers_wordlist.txt
SUFFIXING CHARACTER(S)/WORDS TO WORDLISTS
To suffix the word "test" to each line in the wordlist ;
sed 's/.$/test/' wordlist.txt
or
awk '{print $0 "test"}' wordlist.txt
SUFFIXING NUMERIC VALUES TO WORDLISTS
To suffix 1 digit in sequence from 0 - 9
for i in $(cat wordlist.txt) ; do seq -f $i%01.0f 0 9 ; done > wordlist_numbers.txt
To suffix 2 digits in sequence from 00 - 99for i in $(cat wordlist.txt) ; do seq -f $i%02.0f 0 99 ; done > wordlist_numbers.txt
To suffix upto 2 digits in sequence from 0 - 99 ;
for i in $(cat wordlist.txt) ; do seq -f $i%01.0f 0 99 ; done > wordlist_numbers.txt
for i in $(cat wordlist.txt) ; do seq -f $i%03.0f 0 999 ; done > wordlist_numbers.txt
To suffix upto 3 digits in sequence from 0 - 999 ;
for i in $(cat wordlist.txt) ; do seq -f $i%01.0f 0 999 ; done > wordlist_numbers.txt
INCLUDE CHARACTERS AT SPECIFIC POSITION
To include the word "test" after the first 2 characters ;
sed 's/^../&test/' wordlist.txt
or
sed 's/^.\{2\}/&test/' wordlist.txt
To include the word "test" before the last 2 characters ;
sed 's/..$/test&/' wordlist.txt
or
sed 's/.\{2\}$/test&/' wordlist.txt
REPLACE X NUMBER OF CHARACTERS FROM START OF WORDLIST
To replace the first character of each word with "test" ;
sed 's/^./test/' wordlist.txt
To replace the first 2 characters of each word with "test" ;
sed 's/^../test/' wordlist.txt
To replace the first 3 characters of each word with "test" ;
sed 's/^.../test/' wordlist.txt
or
sed 's/^.\{3\}/test' wordlist.txt
REPLACE/SUBSTITUTE X NUMBER OF CHARACTERS FROM END OF WORDLIST
To replace the last character of each word with "test" ;
sed 's/.$/test/' wordlist.txt
To replace the last 2 characters of each word with "test" ;
sed 's/..$/test/' wordlist.txt
To replace the last 3 characters of each word with "test" ;
sed 's/...$/test/' wordlist.txt
or
sed 's/.\{3\}$/test/' wordlist.txt
REPLACE/SUBSTITUTE CHARACTER(S) AT A CERTAIN POSITION
To subsitute the third character of each word in the wordlist ;
sed -r "s/^(.{2})(.{1})/\1test/" wordlist.txt
or
sed 's/^\(.\{2\}\)\(.\{1\}\)/\1test/' wordlist.txt
To subsitute the third and fourth character of each word in the wordlist with "test" ;
sed -r "s/^(.{2})(.{2})/\1test/" wordlist.txt
To subsitute the fourth character of each word in the wordlist with "test" ;
sed -r "s/^(.{3})(.{1})/\1test/" wordlist.txtTo subsitute the fourth and fifth character of each word in the wordlist with "test" ;
sed -r "s/^(.{3})(.{2})/\1test/" wordlist.txt
NOTE!
If the number of characters that are to be replaced are actually more than there
are characters in the word, the word will remain unaltered.
So if doing
sed -r "s/^(.{3})(.{2})/\1test/" wordlist.txt
4 character letters such as the word 'beta' would not be altered as there is no fifth character.
REVERSE THE DIRECTION OF THE WORDS IN WORDLIST
rev wordlist.txt
REMOVING WORDS WHICH DON'T HAVE 'X' NUMBER OF NUMERIC VALUES
To remove words from wordlist.txt that do not have 3 numeric values
nawk 'gsub("[0-9]","&",$0)==3' wordlist.txt
REMOVE WORDS WITH X NUMBER OF REOCURRING CHARACTERS
Under construction ;)
REMOVING WORDS WHICH HAVE MORE THAN 2 IDENTICAL ADJACENT CHARACTERS
sed '/\([^A-Za-z0-9_]\|[A-Za-z0-9]\)\1\{2,\}/d' wordlist.txt
sed "/\(.\)\1\1/d" wordlist.txt
To delete words with more than 3 identical adjacent characters ;
sed "/\(.\)\1\1\1/d" wordlist.txt
Some great bit of work from Gitsnik on manipulating wordlists to ignore words with
more than 2 adjacent identical characters ;
http://gitsnik.blogspot.com/2011/08/unique-characters-from-crunch-redux.html
http://gitsnik.blogspot.com/2011/08/unique-characters-from-crunch-redux.html
APPENDING WORDS FROM 1 WORDLIST TO ALL THE WORDS IN ANOTHER WORDLIST
See Wordlist Manipulator script at top of page
PERMUTE WORD / WORDLIST
To give all possible variations of a word / wordlist, fantastic bit of perl by Gitsnik ;
Copy / Paste the below and save as permute.pl
chmod 755 permute.pl to make executable.
to test on a single word (for instance "firewall") do ;
cat firewall | ./permute.pl
To test on a wordlist do ;
./permute.pl wordlist.txt
#!/usr/bin/perl
use strict;
use warnings;
my %permution = (
"a" => [ "a", "4", "@", "&", "A" ],
"b" => "bB",
"c" => "cC",
"d" => "dD",
"e" => "3Ee",
"f" => "fF",
"g" => "gG9",
"h" => "hH",
"i" => "iI!|1",
"j" => "jJ",
"k" => "kK",
"l" => "lL!71|",
"m" => "mM",
"n" => "nN",
"o" => "oO0",
"p" => "pP",
"q" => "qQ",
"r" => "rR",
"s" => "sS5$",
"t" => "tT71+",
"u" => "uU",
"v" => "vV",
"w" => ["w", "W", "\/\/"],
"x" => "xX",
"y" => "yY",
"z" => "zZ2",
);
# End config
while(my $word = <>) {
chomp $word;
my @string = split //, lc($word);
&permute(0, @string);
}
sub permute {
my $num = shift;
my @str = @_;
my $len = @str;
if($num >= $len) {
foreach my $char (@str) {
print $char;
}
print "n";
return;
}
my $per = $permution{$str[$num]};
if($per) {
my @letters = ();
if(ref($per) eq 'ARRAY') {
@letters = @$per;
} else {
@letters = split //, $per;
}
$per = "";
foreach $per (@letters) {
my $s = "";
for(my $i = 0; $i < $len; $i++) {
if($i eq 0) {
if($i eq $num) {
$s = $per;
} else {
$s = $str[0];
}
} else {
if($i eq $num) {
$s .= $per;
} else {
$s .= $str[$i];
}
}
}
my @st = split //, $s;
&permute(($num + 1), @st);
}
} else {
&permute(($num + 1), @str);
}
}
..
..
..
Please leave your comments, suggestions, mocking words of wisdom..etc.. so that the post can benefit from
the vast amount of knowledge out there.