
Work In Progress !
==================
A script to facilitate the commonly used options to make an existing
wordlist more to your liking..
Downloads below and based on using the script in Backtrack although it should work
in most Linux environments.
Google code + WIKI ; http://code.google.com/p/wordlist-manipulator/
Edit 21-10-2012
Release of WLM v0.7 ;
http://www.mediafire.com/file/p1tn76qw95hobi4/wlm
Video using WLM in BackBox ;
http://www.youtube.com/watch?v=FpflByHLp1I
--------------------------------------------
INTRO
After my posts from just over 2 years ago (wow... thought I would have learned more by now .. )I thought it would be a good idea to have another, more detailed post on wordlist manipulations based on 'simple' one-liners or simple scripts (sometimes 1 line just doesn't cut it) which can be run over the wordlist.
For some reason I always manage to forget the best way to do the simplest of things using sed and the like, so this is as much a reference for me, as it is hopefully some help to those looking for quick answers !
My intention is that queries on wordlist manipulation posted in the comments are looked at and tested
and then, I will try to post the best solution in doing same.
There will be quite a bit duplication from the previous post on wordlist manipulation, but no harm in that,
I find myself returing to 'old' info all the time..
MANIPULATING WORDLISTS
When you have a wordlist, it often needs fine-tuning or alteration of some kind in order to get the
most out of it, sometimes heavy-duty alteration, other times minor adjustments such as splitting the wordlist into manageable sizes or capitalizing the first letter for instance.
The below examples are based on wordlists that have already been created and need some sort of tweaking or fine tuning.
Of course you can create wordlists from scratch how you like with for instance crunch, however this post is meant solely for altering existing wordlists.
Note that the below examples all done on BackTrack5 and not tested on any other OS.
(although most commands should work on most linux based OS')
SPLITTING WORDLISTS
One of the main issues with wordlists is that they can get hellish big.. and you may need to split them for;
> for easy storage on portable drives,
> some programs only accept a certain maximum wordlist size,
> distributing segments of the wordlists to have tested by others,
etc.
etc.
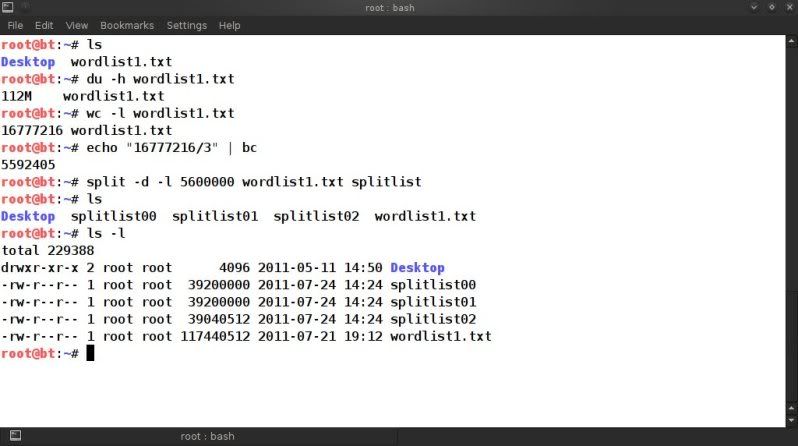
First thing to do is to check the size of the file and how many lines(passphrases) are in it so you can estimate
how you can best split it.
In this case using a 6 digit wordlist with lowecase alpha values only.
Check the size of the wordlist ;
For info on size in bytes ;
du -b wordlist1.txt
orSimple view of size in 'human readable' format (eg. 100K, 100M, 100G);
du -h wordlist1.txt
Get the linecount of the wordlist ;
wc -l wordlist1.txt
So in the above example the size is around 112MB and there are 16777216
lines (so 16777216 passphrases).
When using split to split wordlists, it is best to use split by line count, so that you don't accidentally split the actual words as can happen when you split by size.
Lets say we want to split that file into 3 wordlists, then the above file would need to be split into files containing +-5.500.000 words each.
If you are too lazy to work the little grey cells, let 'bc' do the work for you so you can make an educated guess on how many lines you want to have per split wordlist ;
echo "16777216 / 3" | bc
split -d -l 5600000 wordlist1.txt split-list
-d == giving a numeric suffix to the created split-list prefixes-l == giving the number of lines you want each file to have as a maximum
wordlist1.txt is the input wordlist
splitlist is the prefix for the newly created split files.
JOINING/COMBINING WORDLISTS
To actually combine seperate wordlists to one list, you can use the 'cat' command as follows ;
cat wordlist1.txt wordlist2.txt > combined-wordlist.txt
Depending on the size of your wordlists this can take a wee while..
You can also combine all .txt files in a directory to one larger file ;
cat *.txt > combinedlists.txt
CHANGING THE 'CASE' OF LETTERS IN A WORDLIST
Changing characters in a wordlist at a given position to either lower case or upper case is a frequent necessity.
Of course wordllists can easily be created with the required case in the required position (see my post on using the awesome crunch) however if you have an existing wordlist (which this post is all about) and need
to adjust the cases as required, this is (one of the ways) how to go about it.
First letter;
sed 's/^./\u&/' wordlist.txt
Last letter;
sed 's/.$/\u&/' wordlist.txt
CHANGING LETTERS TO LOWER / UPPER CASE
Changing the first letters of all entries to upper case ;
sed 's/^./\u&/' wordlist.txt
Changing the last letter of all entries to upper case ;
sed 's/.$/\u&/' wordlist.txt
Changing the first letter of all entries to lower case ;
sed 's/^./\l&/' wordlist.txt
Changing the last letter of all entries to lower case ;
sed 's/.$/\l&/' wordlist.txt
Changing all upper case to lower case letters;
tr '[:upper:] ' '[:lower:]' < wordlist.txt
Changing all lower case to upper case letters;
tr '[:lower:]' '[:upper:]' < wordlist.txt
Inverting the case in the words ;
tr 'a-z A-Z' 'A-Z a-z' < wordlist.txt
orsed 'y/abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ/ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz/' wordlist.txt
PREFIXING CHARACTER(S)/WORDS TO WORDLISTS
To prefix the word "test" to all lines in the wordlist ;
sed 's/^./test/' wordlist.txt
or
awk '{print "test" $0 }' wordlist.txt
PREFIXING NUMERIC VALUES TO WORDLISTS
To prefix 1 digit in sequence from 0 - 9 ;
for i in $(cat wordlist.txt) ; do seq -f %01.0f$i 0 9 ; done > numbers_wordlist.txt
To prefix 2 digits in sequence from 00 - 99 ;
for i in $(cat wordlist.txt) ; do seq -f %02.0f$i 0 99 ; done > numbers_wordlist.txt
To prefix upto 2 digits in sequence from 0 - 99 ;
for i in $(cat wordlist.txt) ; do seq -f %01.0f$i 0 99 ; done > numbers_wordlist.txt
To prefix 3 digits in sequence from 000 - 999
for i in $(cat wordlist.txt) ; do seq -f %03.0f$i 0 999 ; done > numbers_wordlist.txt
To prefix upto 3 digits in sequence from 0 - 999 ;
for i in $(cat wordlist.txt) ; do seq -f %01.0f$i 0 999 ; done > numbers_wordlist.txt
SUFFIXING CHARACTER(S)/WORDS TO WORDLISTS
To suffix the word "test" to each line in the wordlist ;
sed 's/.$/test/' wordlist.txt
or
awk '{print $0 "test"}' wordlist.txt
SUFFIXING NUMERIC VALUES TO WORDLISTS
To suffix 1 digit in sequence from 0 - 9
for i in $(cat wordlist.txt) ; do seq -f $i%01.0f 0 9 ; done > wordlist_numbers.txt
To suffix 2 digits in sequence from 00 - 99for i in $(cat wordlist.txt) ; do seq -f $i%02.0f 0 99 ; done > wordlist_numbers.txt
To suffix upto 2 digits in sequence from 0 - 99 ;
for i in $(cat wordlist.txt) ; do seq -f $i%01.0f 0 99 ; done > wordlist_numbers.txt
for i in $(cat wordlist.txt) ; do seq -f $i%03.0f 0 999 ; done > wordlist_numbers.txt
To suffix upto 3 digits in sequence from 0 - 999 ;
for i in $(cat wordlist.txt) ; do seq -f $i%01.0f 0 999 ; done > wordlist_numbers.txt
INCLUDE CHARACTERS AT SPECIFIC POSITION
To include the word "test" after the first 2 characters ;
sed 's/^../&test/' wordlist.txt
or
sed 's/^.\{2\}/&test/' wordlist.txt
To include the word "test" before the last 2 characters ;
sed 's/..$/test&/' wordlist.txt
or
sed 's/.\{2\}$/test&/' wordlist.txt
REPLACE X NUMBER OF CHARACTERS FROM START OF WORDLIST
To replace the first character of each word with "test" ;
sed 's/^./test/' wordlist.txt
To replace the first 2 characters of each word with "test" ;
sed 's/^../test/' wordlist.txt
To replace the first 3 characters of each word with "test" ;
sed 's/^.../test/' wordlist.txt
or
sed 's/^.\{3\}/test' wordlist.txt
REPLACE/SUBSTITUTE X NUMBER OF CHARACTERS FROM END OF WORDLIST
To replace the last character of each word with "test" ;
sed 's/.$/test/' wordlist.txt
To replace the last 2 characters of each word with "test" ;
sed 's/..$/test/' wordlist.txt
To replace the last 3 characters of each word with "test" ;
sed 's/...$/test/' wordlist.txt
or
sed 's/.\{3\}$/test/' wordlist.txt
REPLACE/SUBSTITUTE CHARACTER(S) AT A CERTAIN POSITION
To subsitute the third character of each word in the wordlist ;
sed -r "s/^(.{2})(.{1})/\1test/" wordlist.txt
or
sed 's/^\(.\{2\}\)\(.\{1\}\)/\1test/' wordlist.txt
To subsitute the third and fourth character of each word in the wordlist with "test" ;
sed -r "s/^(.{2})(.{2})/\1test/" wordlist.txt
To subsitute the fourth character of each word in the wordlist with "test" ;
sed -r "s/^(.{3})(.{1})/\1test/" wordlist.txtTo subsitute the fourth and fifth character of each word in the wordlist with "test" ;
sed -r "s/^(.{3})(.{2})/\1test/" wordlist.txt
NOTE!
If the number of characters that are to be replaced are actually more than there
are characters in the word, the word will remain unaltered.
So if doing
sed -r "s/^(.{3})(.{2})/\1test/" wordlist.txt
4 character letters such as the word 'beta' would not be altered as there is no fifth character.
REVERSE THE DIRECTION OF THE WORDS IN WORDLIST
rev wordlist.txt
REMOVING WORDS WHICH DON'T HAVE 'X' NUMBER OF NUMERIC VALUES
To remove words from wordlist.txt that do not have 3 numeric values
nawk 'gsub("[0-9]","&",$0)==3' wordlist.txt
REMOVE WORDS WITH X NUMBER OF REOCURRING CHARACTERS
Under construction ;)
REMOVING WORDS WHICH HAVE MORE THAN 2 IDENTICAL ADJACENT CHARACTERS
sed '/\([^A-Za-z0-9_]\|[A-Za-z0-9]\)\1\{2,\}/d' wordlist.txt
sed "/\(.\)\1\1/d" wordlist.txt
To delete words with more than 3 identical adjacent characters ;
sed "/\(.\)\1\1\1/d" wordlist.txt
Some great bit of work from Gitsnik on manipulating wordlists to ignore words with
more than 2 adjacent identical characters ;
http://gitsnik.blogspot.com/2011/08/unique-characters-from-crunch-redux.html
http://gitsnik.blogspot.com/2011/08/unique-characters-from-crunch-redux.html
APPENDING WORDS FROM 1 WORDLIST TO ALL THE WORDS IN ANOTHER WORDLIST
See Wordlist Manipulator script at top of page
PERMUTE WORD / WORDLIST
To give all possible variations of a word / wordlist, fantastic bit of perl by Gitsnik ;
Copy / Paste the below and save as permute.pl
chmod 755 permute.pl to make executable.
to test on a single word (for instance "firewall") do ;
cat firewall | ./permute.pl
To test on a wordlist do ;
./permute.pl wordlist.txt
#!/usr/bin/perl
use strict;
use warnings;
my %permution = (
"a" => [ "a", "4", "@", "&", "A" ],
"b" => "bB",
"c" => "cC",
"d" => "dD",
"e" => "3Ee",
"f" => "fF",
"g" => "gG9",
"h" => "hH",
"i" => "iI!|1",
"j" => "jJ",
"k" => "kK",
"l" => "lL!71|",
"m" => "mM",
"n" => "nN",
"o" => "oO0",
"p" => "pP",
"q" => "qQ",
"r" => "rR",
"s" => "sS5$",
"t" => "tT71+",
"u" => "uU",
"v" => "vV",
"w" => ["w", "W", "\/\/"],
"x" => "xX",
"y" => "yY",
"z" => "zZ2",
);
# End config
while(my $word = <>) {
chomp $word;
my @string = split //, lc($word);
&permute(0, @string);
}
sub permute {
my $num = shift;
my @str = @_;
my $len = @str;
if($num >= $len) {
foreach my $char (@str) {
print $char;
}
print "n";
return;
}
my $per = $permution{$str[$num]};
if($per) {
my @letters = ();
if(ref($per) eq 'ARRAY') {
@letters = @$per;
} else {
@letters = split //, $per;
}
$per = "";
foreach $per (@letters) {
my $s = "";
for(my $i = 0; $i < $len; $i++) {
if($i eq 0) {
if($i eq $num) {
$s = $per;
} else {
$s = $str[0];
}
} else {
if($i eq $num) {
$s .= $per;
} else {
$s .= $str[$i];
}
}
}
my @st = split //, $s;
&permute(($num + 1), @st);
}
} else {
&permute(($num + 1), @str);
}
}
..
..
..
Please leave your comments, suggestions, mocking words of wisdom..etc.. so that the post can benefit from
the vast amount of knowledge out there.
Hey, How do you save the new list when you use that kind of cmd?
ReplyDeleteLike :ed 's/^\(.\{2\}\)\(.\{1\}\)/\1test/' wordlist.txt
It will show new passphrases on shell but don't apply it on the word list :/
ed 's/^\(.\{2\}\)\(.\{1\}\)/\1test/' wordlist.txt > [newfilenamw]
Deletehey there, you can put an "-i" in front of the wordlist ot have the changes take effect to the file being used.
ReplyDeleteIf you wanted to keep the original file as is and print changes to a different file, then just add "> newfile.txt" to the end of the command.
Changing all upper case to lower case letters;
ReplyDeletesed 's/./\l&/g' wordlist.txt
Changing all lower case to upper case letters;
sed 's/./\u&/g' wordlist.txt
Hope this is usefull.
The Combinator worked great as is, Much Thanks
Hi
ReplyDeleteI'm tryng to customize a wl and got a problem that I can't resolve myself and in google...
In this small script if my file wordlist is large than 150 mb I got a error in xmalloc
Have you got a experience like this?
y.sh
for i in $(cat wordlist.txt) ; do
......commands;
done | sort | uniq
-----------------------------------------------
./y.sh: xmalloc: ../bash/make_cmd.c:172: cannot allocate 8 bytes (2908979200 bytes allocated)
Have you tried something along the lines of ;
ReplyDeletecat wordlist.txt | sort | uniq > test.txt
Couple months late to the party but rather than doing:
ReplyDeletefor i in $(cat wordlist.txt); do
Use:
for i in $(sort -u < wordlist.txt); do
Or something similar:
for i in $(cat wordlist.txt | sort | uniq); do
Or
for i in $(cat wordlist.txt | sort -u); do
And so on.
Your expertise greatly appreciated as always ;)
Deletehow about if i run "/crunch 1 1 1234567890 -p > test "how do i sed that test file so that it cuts all lines at 4 characters so its like so
ReplyDelete1234
2345
1256
and so on thank you in advance
Hey Anonymous..
DeleteSO you want to try all permutations of '1234567890' and only show the first 4 digits of the permutations.
This means you want to remove the last 6 digits from the results, for which you
could try this ;
./crunch 1 1 -u -p 1234567890 | sed 's/^.\{6\}//' > test
Let me know if it is what you were thinking of.
Or of course you can create the file in its totality and use WLM to cut it down
to what you want with the option 9 followed by option 2.. ;)
Laters - TAPE
omg i have been looking for weeks how to do this thank you the sed command works perfect but the wlm not sure what that is or how to fire it up but thank you so much if you know how to pipe that same command in to pyrit that would be super helpful sed is so very confusing to me
ReplyDeleteFor using WLM in backtrack5, simply enter ;
Delete./wlm
in the command line in the directory where the file is.
(of course if the file is called wlm_v0-3 then start by
using ./wlm_v0-3)
As for using pyrit.. pyrit is for WPA/WPA2 passwords, so
a 4 digit password is not of any use.
WLM and what it is, is mentioned at the top of this page by the way .. ;)
Deleteo i was just saying a 4 digit password to get the idea down i intend on using this logic to crack 10 digit mac address passwords. so do you know if i can pipe sed to pyrit and by the way i am sorry i read two of your post in full detail this is the 3rd one i came by and i just fly through it looking how to use sed i will be sure to read this one when i have time and see what wlm is all about and thank you for your time it means allot
ReplyDeleteWell it is possible of course, you could have a look at my post on crunch to
Deletesee what usual piping command from crunch would look like.
In this case you just pipe the output from crunch though sed and from there
through to pyrit ;
./crunch 1 1 -u -p 1234567890 | sed 's/^.\{2\}//' | pyrit -i - -r /pathto/capfile.cap -e ESSID attack_passthrough
To make it more easily read, breaking each command with backslash
(to ensure the command continues to be read from next line) based on being
in the crunch directory;
./crunch 1 1 -u -p 1234567890 | \
sed 's/^.\{2\}//' | \
pyrit -i - -r /pathto/capfile.cap -e ESSID attack_passthrough
You could also of course just use the 'cut' function to cut the first X number
Deleteof characters from the wordlist ;
For first 4 ;
./crunch 1 1 -u -p 1234567890 | cut -c 1-4 | blah blah
For first 8;
./crunch 1 1 -u -p 1234567890 | cut -c 1-8 | blah blah
etc
etc
Have anyone problems to open the file ./wlm ???
ReplyDeleteI got the failure, permission denied.
Whats wrong?
Have you ensured that the file is executable ?
DeleteFirst make sure that file is indeed named 'wlm'
Then do ;
chmod 755 wlm
then try again with
./wlm
Hi Tape
ReplyDeleteThank you for your hard work, your tutorials are a great help to me.
Can I ask in the section REMOVING WORDS WHICH HAVE MORE THAN 2 IDENTICAL ADJACENT CHARACTERS
Is there a way to see if a character appears more than n times in a line and not just adjacently ? So abcda would be deleted (a at start and appears again at end) but abcde wouldn't ?
Also could you please explain what the part \1\ means in the line below..
sed '/\([^A-Za-z0-9_]\|[A-Za-z0-9]\)\1\{2,\}/d' wordlist.txt
Thank you for your help.
Hey there, glad you liking the blog !
DeleteI will try to get the cobwebs out of the head and have a peek at
how best to do that, so to clarify ;
- Delete any word from a list that has N number of identical characters.
Will try to put the brain in gear.. ;) reverting !
As for the \1\
Actually it is only \1 as the second backslash is the escape character
for the {
\1 is referring to the first part of the sed command ;
\[^A-Za-z0-9_]
Thank you Tape for replying to me.
Delete- Delete any word from a list that has N number of identical characters.
Thats exactly it ! :o)
I was wondering if I can interest you in joining in on a conversation on the hashcat forum ? I think you are just the chap we need to help us !
http://hashcat.net/forum/thread-1201.html
Hi Tape
ReplyDeleteI think the problem is solved by a friend of mine. (M@lik)
sed "/\(.\).*\1.*\1/d"
I would still like your input on the forum though if you have time.
hehe, good to see you got the help you needed !
DeleteI will be adding some similar info to the blog post as well, but bit busy
at the mo..
Laters - TAPE
hi! may i ask u a relevant to list generating question.
ReplyDeleteI am using crunch trying to create a list that will import a txt file with Names lets say :john mary etc.. and will explort john11 john12... ..mary21 mary22. i can do that name by name but my supposed list has many names and it is not easy to do those one by one. Thanks.
Hey,
DeleteThe code to do that is mentioned in the post under the Suffix section...
...
To suffix upto 2 digits in sequence from 0 - 99 ;
for i in $(cat wordlist.txt) ; do seq -f $i%01.0f 0 99 ; done > wordlist_numbers.txt
...
Otherwise download the script I made "wlm_v0-3" and use the suffix
option, that will do what you want.
Hi thanks for the post i read it again and i noticed i bypassed the info that was already there. I spent some time with the posted perl script although i am not familiar with perl i have noticed that in line 58 there is a slash \ missing before n. Besides that the script works but i have a huge question mark for you once more :)
ReplyDeleteLet me give an example
a wordlist contais a word Ian and i want to use script to produce replacements-permutations. This script will give me 14n for example but not 1an or i4n meaning we lose the intermediate permutations because its performing changes alltogether and not in combinations. Your thoughts please.
Hey Jules,
DeleteHave to say I am not 100% clear on what you are trying to do..
(I know its sometimes hard to write what u want accomplished)
Can you give all the results you want to achieve for for instance
the word Ian ?
Sure i ll try better, lets suppose we want i => 1
ReplyDeleteand a => 4
#input wordlist
ian
#output wordlist
ian
i4n
1an
14n
i am trying to say that the script posted above misses
the 2nd and 3rd line of the output list. because it permutes all at once and not in combinations.
so it produces only the 4rth line.
Hey Jules,
DeleteMy brain must be on holiday.. I can't seem to get in my mind what
you exactly need..
Let me stare at it a little longer or wait for someone with more smarts
to have a look ;)
Hey Tape,
ReplyDeleteFirst off, you have a great blog here...I constantly find my self using it for notes for various things.
I'm currently working on a script for generating password lists through various website APIs but im lacking any real way of testing the actual output of these lists. Im wondering if you know of anywhere i can go to download massive lists of (preferably unsalted for now) password hashes. I've been searching for the linkedin hashes specifically but i cant find them now. I basicly just want to test my pass lists to see if im coming up way short on my objectives or if im at least on the right track.
Thanks for any input, also when i get this closer to being finished would you like to have a look and see if you can improve on it at all.
Reaver9
Excuse me but i have to notice a bug.
ReplyDeleteI had to split a very big file into file of about 5000000 lines, and there will be about 200 files, but when the tool splitted 99 files, it said that it could not continue because the avaible numbers are out or something like this.
Why it could not create more than 100 files?
Hi there, thanks for your input !
DeleteI will have a look and see if I can replicate the problem.
Watch this space..
I tried with the split command (split -l 550000 file.txt Splitted), and it splits file with an lowercase suffix..
ReplyDeleteUnfortunately, this don't worked for me, i have to split the main file into other two,and then again, but I think that it could be helpful for your program.
P.s. sorry for my english
I think also that it could be helpful a function that delete the words that do not satisfy some requirements (like the 8-chars for wpa).
ReplyDeleteOr, can you help me to do this?I have a list of hundreds file to process..
Can you specify a bit more what you mean ?
DeleteThere is already the option to delete words that do not follow
certain 'from-to' length requirements with the optimization option.
In the latest version, which not officially released yet, posted I have also included an option to be able to delete words of a certain length.
http://www.mediafire.com/file/m89a8wgo7moul3n/wlm_v0-6
Yes, I've just now read the source, and I was missing the pw-inspector, so the optimitation for wpa was not working for me.
ReplyDeleteIn my case, I can't use your maniipulator /that in other situations helped me a lot/, because I have to do the same operation for many files, so I created a script that calls pw-inspector.
Thanks for your avaibility man!
Ah so your not using backtrack. Then yes, that would make sense ;)
DeleteNo worries, always glad to get feedback and enjoy hearing that people are actually using my scribbles :D
I cannot seem to replicate the problem with the file splitting you were mentioning..
ReplyDeleteI tested on a file with about 14 million lines and it worked fine (file size +- 140MB.
Are you sure it wasnt a space problem your end ?
I misread your comment, and have now been able to replicate the issue ;
Delete"Working ..
split: output file suffixes exhausted"
Basically it seems that my idea of always having a numeric suffix (which I prefer) is limited to 99..
Will have a look at that, thanks for the input/bug report !!
The default that split uses is 2 suffixes, so when 99 is reached it basically finishes, I had not taken that into consideration when I wrote the script, so will see if I can include the -a switch in split to increase the suffix possibilities on next release.
DeleteThanks again !
I have updated the script and will release v0-7 in due course.
DeleteThe script now creates the number of suffixes based on the estimated number of files that will be created.
Thanks again for the report on the bug.
Hi Tape, first let me say good tool and thanks, i have a suggestion for the menu option 9 "Removal /Deletion options", and option 4 "Remove words containing specific characters.", the suggestion is, can delete more of 1 character, example:
ReplyDeleteI want to delete all lines with:
@#/(=,etc,etc
Maybe you can add this option if you wish.
i want to combine word in wordlist like:
ReplyDeleteexample
i have wordlist like this
apple
banana
citrus
and i want make new wordlist like
appleappleapple
appleapplebanana
applebananacitrus
applebananabanana
applecitruscitrus
applecitrusbanana
bananabananabanana
bananabananabanana
bananabananaaple
bananabananacitrus
bananaaplecitrus
bananaappleapple
bananacitruscitrus
...
etc
thank's for your advices
I would say that the easiest way to accomplish this is to run the rar cracking program cRARk and save the output...
ReplyDeleteSo, checkout this post ;
http://adaywithtape.blogspot.nl/2010/02/rar-password-cracking-with-crark.html
the last entries are the ones you would want to focus on.
Create a wordlist.def file with entries as follows ;
$w="wordlist.txt"
##
$w$w$w
Run cRARk on a rar file as follows ;
crark.exe -c -pwordlist.def -v rarfile.rar > test.txt
hit Enter twice..
Will look into other ways for this with bash script.
hi i want to convert a few wordlists so that they are all upper case A-z and also remove all the numbers and then pipe it to aircrack or pyrit can any one help pls ???
ReplyDeleteHiya David,
DeleteTry the below syntax ;
sed -e '/[0-9]/d' -e 's/\(.*\)/\U\1/' wordlist.txt | aircrack-ng blah blah
Awesome blog sir, keep up the good work! "BTnoob101"
ReplyDeleteHi, nice topic you have here :)
ReplyDeleteI was wondering how to clean the wordlist from characters that is not supported, like the NUL, ETX, STX, etc... i see those when open a file with notepad++.
I found this: tr -cd '\11\12\15\40-\167' < IN.file > OUT.file
but i think this will remove other chars that is shouldn't to be removed like a double quotes ?!
I always use a version of my name first then last or parial first then last or first initial then last and then any of them could be followed by 1 to four numbers raning from 0 to 9999
ReplyDeleteI also randomize every letter upper or lower what would be the schema or pattern to set up a wordlist tailored to me for my own accounts
pass will always include at least 1 upper case one lower case and one number and no specials
IE --- Sglover79 first initial last name two digits or Stephglover1979 or StEphaNIeGlover2011 that being the longest pattern i use ful first full last and four numbers
i also some time use a few other words with 2-4 numbers as well including my childs name and initials faith,god,jesus ballin jayden jay Ajayden anthony anthonyj anthomnyjayden
rtvc you get the idea pass word will alway sbe between 6 min and 20 max
efrom what im reading im going to hav eto output multiple lists and combine etc ?
Thats quite a bit to do and to be honest you would have to write a script to do something like that.
DeleteI have been thinking about a script following the ideas CUPP is based on, but there can be so many variables, its difficult to know how to even ask for the input !
well i would think the floowing would be great for people trying to make a list such as that
Delete1. min pass length
2. max pas length
3. single letters to be used ie s g <0-- for first and last initial etc
by doing this you can let them input first or last initial
4 apend single letters to front y/n
5 append single letters to rear y/n
6. numbers to be added to words leave 0- for no random numbers added
7. input words/numbers/letters to use a whole words/items in list
IE steph stephanie glover faith etc you could ALSO USE number strings that you knwo may be used liek 79 2012 rather then a range of numbers to lower the size of your list etc and the scritp treats all these as non variable must stay the same ltter or number items minus cap or lower case variance and then have the script combine all those in any combination that fits inside the minimum and maximum password length
8. upper and lower case for single letters ? y/n
this would cause the single letters enttered to be added as upper and lower for words
ie Sglover sglover would both generate
9 maximum allowed number of single letters fornt or rear of full words ? ie i could put 2 and it would make sgglover or gloversg
10. capitalize and lower case for first letter of full words ? so ie i could get out sgglover sgGLOVER etc
11. thats all i can think of at the moment but with thosze tools anyone who uses any kind of repeated pattern or anyone you can do some scoial eng on should be prety sucessfull
Can you please upload all your generated wordlist.. It makes things easier.. I created a program that generates all permutations of characters but it is taking eternity.. Your help is really really much appreciated.. Thanks..
ReplyDeletefantastic work thanks! Question is there a command to edit a wordlist to keep only words starting with a certain set of characters. For instance what if I wanted to only keep words that start with an upper or lower case T.
ReplyDeleteWell, you could try a sed command for that ;
Deletesed -n '/^t/p;/^T/p' wordlist.txt
awesome program.
ReplyDeletehow to remove duplicates from a dictionary type: 1q1w1, W4WtyW, 0t0qw, PfP00PzxP.....
Getting a carriage return using the code to add a suffix to wordlist
ReplyDelete